High Availability
Overview
High Availability (HA) is the feature that restarts a virtual machine (VM) on a different hypervisor when the hypervisor it was running on stops responding. The goal is to keep customer VMs up even if a physical server fails.
HA only works when the VM's disks live on storage that more than one hypervisor can read. If a VM's disk lives only on the dead hypervisor's local disk, there is nothing to restart on another node.
Concepts
A few terms used in this page:
- Hypervisor. A physical server in your fleet that runs customer VMs.
- Hypervisor group. A logical grouping of hypervisors, usually one per region or data center. HA is enabled at this level.
- Shared storage. Storage that more than one hypervisor can read and write at the same time. Ceph (a distributed block storage system) and NFS (a shared filesystem over the network) are the two supported options. Storage that lives only on one hypervisor's local disk is not shared storage.
- IPMI. Intelligent Platform Management Interface. A separate network port on the physical server motherboard that lets the master power the server off even when the operating system is hung. Used by HA to make sure a hypervisor that looks dead is actually off, so two hypervisors do not try to run the same VM at the same time.
- Fencing. Forcing a suspected-dead hypervisor off via IPMI before starting its VMs elsewhere. Without fencing, you can end up with two copies of the same VM running on two hypervisors, both writing to the same shared disk. That corrupts data.
- Evacuation. Restarting the VMs from a dead hypervisor onto other hypervisors in the same group.
- HA-eligible instance. A VM that the operator has flagged as one HA should restart. VMs not flagged are left where they are.
How HA works
Every 30 seconds the master runs the ha:monitor scheduled task. For each HA-enabled hypervisor it:
- Pings the hypervisor.
- Calls the hypervisor's
/healthAPI endpoint. - If both fail, increments a failure counter for that hypervisor.
- When the failure counter reaches the configured threshold (default 3, so 90 seconds of failure), marks the hypervisor as failed.
- Sends an IPMI power-off to the failed hypervisor (fencing).
- Picks each HA-eligible VM on the failed hypervisor and restarts it on another healthy hypervisor in the same group.
- Logs every step to the HA events log.
If the failed hypervisor recovers (responds to health checks again), it is marked back as up. VMs that were evacuated stay where they were evacuated to.
Prerequisites
You cannot enable HA usefully without all three of these in place:
- Shared storage attached to every hypervisor in the group. Ceph (recommended) or NFS. See Installation > Shared Storage > Ceph for setup.
- A hypervisor group with at least two hypervisors, all attached to the same shared storage and all the same CPU architecture (a VM cannot live-restart on a different architecture).
- IPMI configured on every hypervisor. IPMI enabled in BIOS/UEFI, network reachable from the master, and credentials stored in the hypervisor's record.
You also need the ipmitool package installed on the master:
# Debian / Ubuntu
apt-get install ipmitool
# RHEL family
yum install ipmitool
If a VM's disk is on the dead hypervisor's local disk, HA cannot restart the VM elsewhere because no other hypervisor can read the disk. Enabling the HA flag on such a VM has no effect when the host dies.
Admin steps
1. Configure IPMI on every hypervisor
For each hypervisor in the group:
- Open the admin panel and navigate to Compute > Hypervisors.
- Edit the hypervisor.
- In the IPMI Configuration section fill in:
- IPMI Host - IP or hostname of the IPMI interface.
- IPMI Port - usually
623. - IPMI Username and IPMI Password.
- Save.
From the master, test the credentials work:
ipmitool -I lanplus -H <ipmi-host> -U <username> -P <password> power status
You should see Chassis Power is on. If you get a timeout or authentication failure, fix that before continuing. HA fencing will fail the same way at runtime.
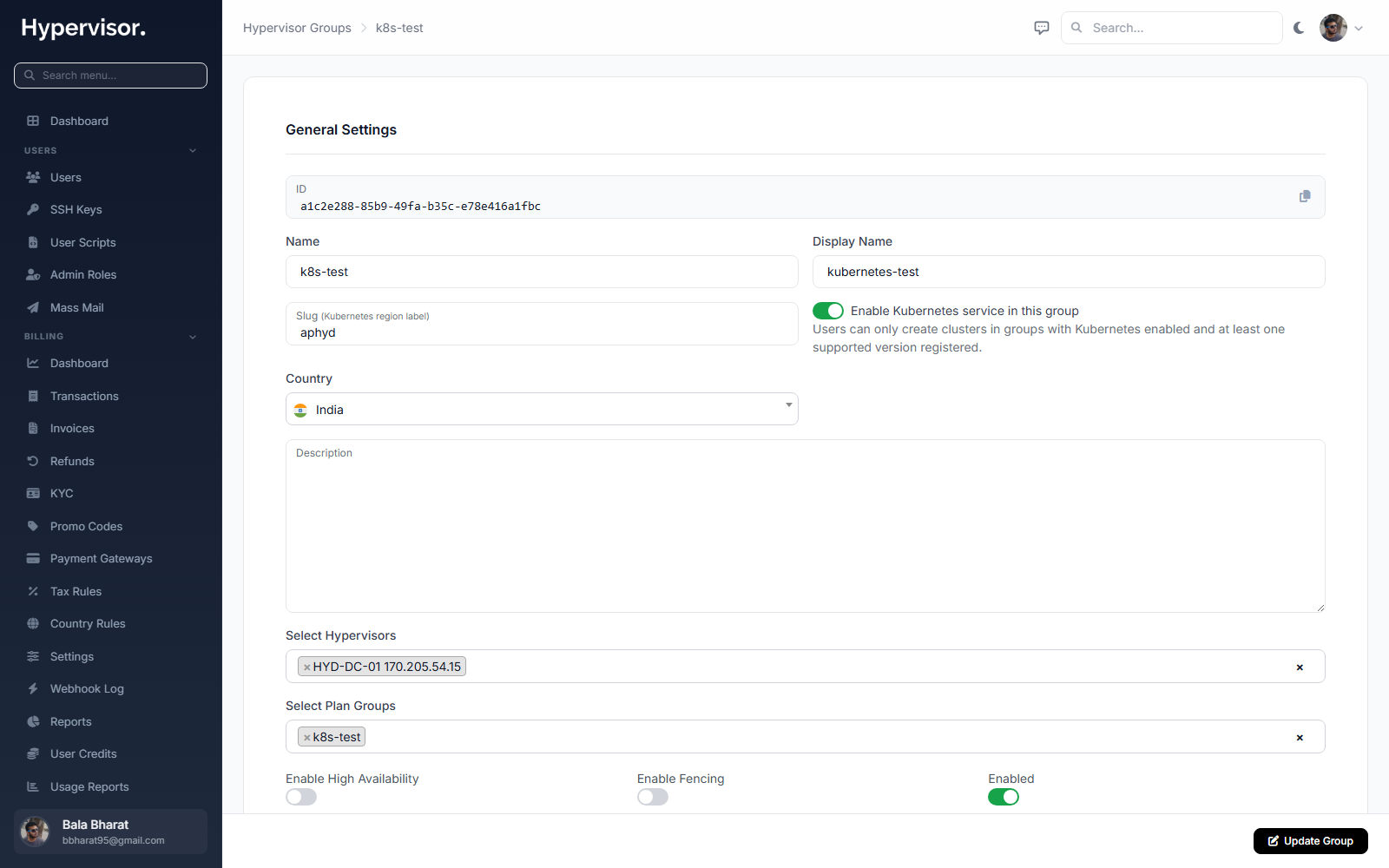
2. Enable HA on the hypervisor group
The HA toggle and its options only appear on an existing hypervisor group, not on the Create form. Create the group first if you do not have one yet (just name + at least one hypervisor), then come back to edit it.
- Navigate to Compute > Hypervisor Groups.
- Open the group whose hypervisors should have HA.
- Toggle HA Enabled on. The Failure Threshold, Fencing, and Evacuation options appear once the toggle is on.
- Configure:
- Failure Threshold - how many consecutive failed health checks before the group declares the hypervisor dead. Default 3 (90 seconds at 30 second intervals). Lowering it makes HA react faster but also makes it more likely to trip on a brief network blip.
- Fencing Enabled - sends an IPMI power-off to the failed hypervisor before evacuating its VMs. Required to prevent split-brain corruption on shared storage.
- Evacuation Enabled - leave this on for normal HA. Off means the group only logs the failure and does not restart anything.
- Save.
3. Flag instances as HA-eligible
HA only restarts VMs that are flagged. Existing VMs are not flagged by default.
- Open the instance detail page.
- Edit settings.
- Toggle HA Enabled on.
- Set Max Restart Attempts - how many times HA will retry restarting this VM elsewhere before giving up. Default 3.
Only flag VMs whose disks live on shared storage. Flagging a local-disk VM has no effect when the host dies.
4. Review the HA events log
The events log is the only HA UI that captures what is actually happening. Open System > HA Events.
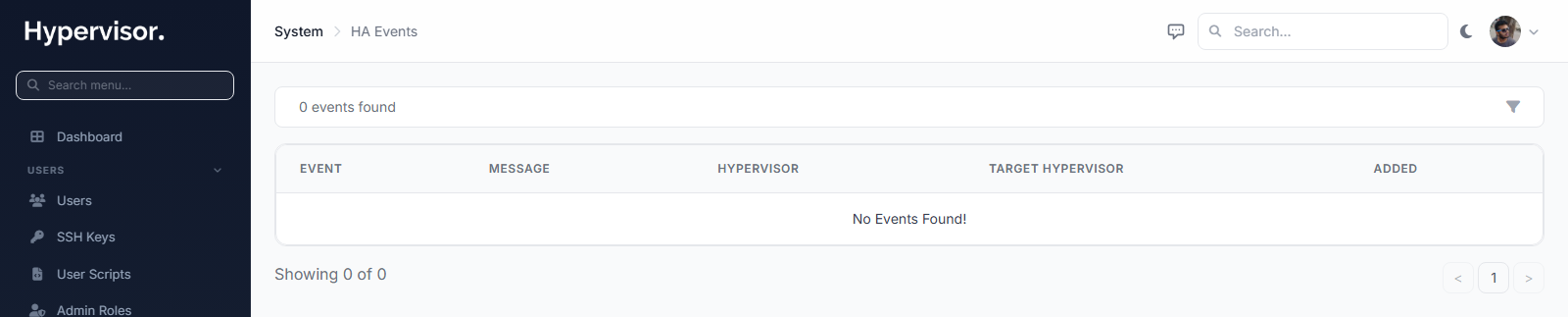
Each row shows the event type, timestamp, the hypervisor or instance involved, and any extra metadata such as which hypervisor a VM was evacuated to. The four event types are:
| Event | When it fires |
|---|---|
hypervisor_up | Health checks pass after the hypervisor was previously marked down. |
hypervisor_down | Consecutive failures reached the threshold. |
hypervisor_fenced | IPMI power-off was sent (just before evacuation begins). |
instance_evacuated | One VM was restarted on a different hypervisor. |
There is no separate dashboard for HA configuration. Configuration lives on the hypervisor group and per-instance pages described above, and the only operational view is this events log.
What end users see
Nothing, in the steady case. HA is operator-facing.
When a host dies and HA evacuates a user's VM:
- The VM appears to reboot. The end user sees the VM go unreachable and come back, the same as a normal restart.
- In the user panel the VM's hypervisor field changes to the new host.
- No notification is sent to the end user by default.
If you want end users to know their VM was evacuated, you have to wire that up through the events / email system separately.
Capacity planning
When a hypervisor fails, every HA-eligible VM on it has to fit somewhere else in the group. If the rest of the group is already full, evacuation will fail for some VMs.
Plan capacity so the group can lose one hypervisor (N+1) or two (N+2) and still hold every VM. A simple rule: total RAM in use across the group should stay below (total RAM in the group) - (RAM of the largest hypervisor).
Troubleshooting
A hypervisor was marked down but never fenced
IPMI is probably misconfigured. Check that:
- The IPMI Host / Username / Password on the hypervisor record are current.
- The master can reach the IPMI interface over the network.
ipmitool -I lanplus -H <host> -U <user> -P <pass> power statusreturns the chassis state.
Fix IPMI, then if the hypervisor is still actually down, reset the failure state and let HA retry.
VMs were not evacuated even though the host was fenced
Check each VM:
- Is the HA Enabled flag on?
- Does the VM's disk live on shared storage? Local-disk VMs are skipped.
- Is the destination hypervisor group out of capacity? Look for evacuation errors in the events log.
False positives during network blips
A 30 second outage will not trip HA at default settings (threshold = 3 = 90 seconds). If you are seeing repeated false trips, raise the threshold on the hypervisor group. Do not lower it below 3.
Related pages
- Installation > Shared Storage > Ceph - required before HA is useful.
- Compute > Hypervisor Groups - where the HA toggle lives (configured under Admin Setup).